Meta Platforms Inc. has revealed a pair of enormously highly effective graphics processing unit clusters that it says can be used to help the coaching of next-generation generative synthetic intelligence fashions, together with the upcoming Llama 3.
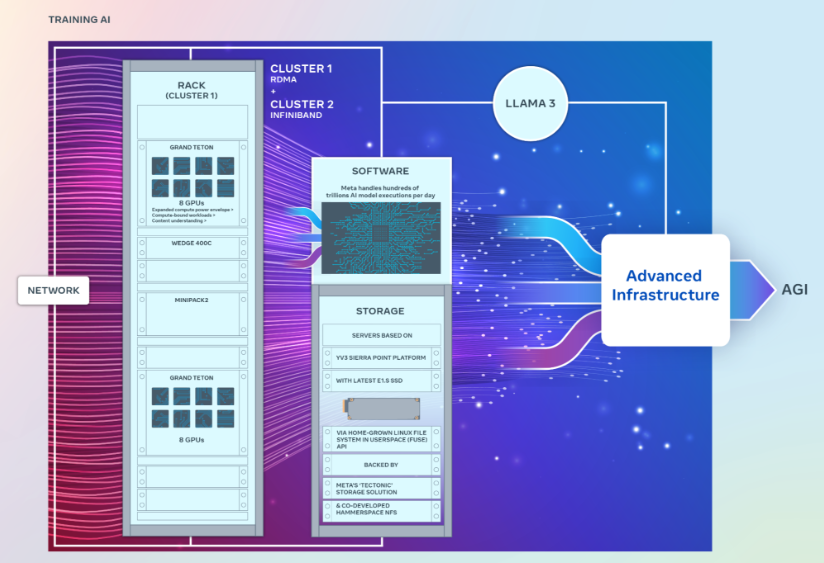
Meta engineers Kevin Lee, Adi Gangidi and Mathew Oldham defined in a weblog put up that the 2 24,576-GPU knowledge heart scale clusters had been constructed to help a lot bigger and extra advanced generative AI fashions than those it has beforehand launched, comparable to Llama 2, a preferred open-source algorithm that rivals OpenAI’s ChatGPT and Google LLC’s Gemini. They may also support in future AI analysis and growth, the engineers stated.
Every cluster packs hundreds of Nvidia Corp.’s strongest H100 GPUs, and they’re much larger than the corporate’s earlier giant clusters, which comprise round 16,000 Nvidia A100 GPUs.
Meta has reportedly been busy snapping up hundreds of Nvidia’s newest chips, and a report from Omdia not too long ago claimed that the corporate has change into one of many chipmaker’s largest prospects. Now we all know why.
Meta stated it’s going to use the brand new clusters to fine-tune its current AI techniques and prepare newer, extra highly effective ones, together with Llama 3, the deliberate successor to Llama 2. The weblog put up marks the primary time that Meta has confirmed it’s engaged on Llama 3, although it was extensively suspected of doing so. The engineers stated that Llama 3’s growth is at the moment “ongoing” and didn’t reveal after we would possibly count on it to be introduced.
In the long term, Meta goals to create synthetic common intelligence or AGI techniques that can be way more humanlike when it comes to creativity than current generative AI fashions. Within the weblog put up, it stated the brand new clusters will assist to scale these ambitions. Moreover, Meta revealed it’s engaged on evolving its PyTorch AI framework, getting it able to help a lot bigger numbers of GPUs.
Below the hood
Though the 2 clusters each have precisely the identical variety of GPUs interconnected with 400 gigabytes-per-second endpoints, they characteristic completely different architectures. Considered one of them options distant direct reminiscence entry or RDMA over a converged Ethernet community material that’s primarily based on Arista Networks Inc.’s Arista 7800 with Wedge400 and Minipack2 OCP rack switches. The opposite is constructed utilizing Nvidia’s personal community material expertise, known as Quantum2 InfiniBand.
The clusters had been each constructed utilizing Meta’s open GPU {hardware} platform, known as Grand Teton, which is designed to help large-scale AI workloads. Grand Teton is alleged to characteristic four-times as a lot host-to-GPU bandwidth as its predecessor, the Zion-EX platform, twice as a lot compute and knowledge community bandwidth, and twice the ability envelope.
Meta stated the clusters incorporate its newest Open Rack energy and rack infrastructure structure, which is designed to supply higher flexibility for knowledge heart designs. In keeping with the engineers, Open Rack v3 permits for energy cabinets to be put in anyplace contained in the rack, moderately than bolting it to the busbar, enabling extra versatile configurations.
As well as, the variety of servers per rack is customizable, enabling a extra environment friendly stability when it comes to throughput capability per server. In flip, that has made it doable to scale back the full rack rely considerably, Meta stated.
By way of storage, the clusters make use of a Linux-based Filesystem in Userspace software programming interface, which is backed up by Meta’s distributed storage platform Tectonic. Meta additionally partnered with a startup known as Hammerspace Inc. to create a brand new parallel community file system for the clusters.
Lastly, the engineers defined that the clusters are primarily based on the YV3 Sierra Level server platform and have its most superior E1.S solid-state drives. The group famous that they personalized the cluster’s community topology and routing structure, and deployed Nvidia’s Collective Communications Library of communications routines which might be optimized for its GPUs.
Extra GPUs to return
Meta talked about within the weblog put up that it stays totally dedicated to open innovation in its AI {hardware} stack. They reminded readers that the corporate is a member of the not too long ago introduced AI Alliance, which goals to create an open ecosystem that may improve transparency and belief in AI growth and guarantee everybody can profit from its improvements.
“As we glance to the long run, we acknowledge that what labored yesterday or at this time will not be enough for tomorrow’s wants,” the engineers wrote. “That’s why we’re continuously evaluating and enhancing each facet of our infrastructure, from the bodily and digital layers to the software program layer and past.”
Meta additionally revealed that it’s going to proceed shopping for up extra of Nvidia’s H100 GPUs and intends to have over 350,000 by the tip of the yr. These can be used to proceed constructing out its AI infrastructure, and we are going to possible see much more highly effective GPU clusters emerge earlier than too lengthy.
Be a part of the neighborhood that features greater than 15,000 #CubeAlumni consultants, together with Amazon.com CEO Andy Jassy, Dell Applied sciences founder and CEO Michael Dell, Intel CEO Pat Gelsinger, and plenty of extra luminaries and consultants.
“TheCUBE is a vital associate to the trade. You guys actually are part of our occasions and we actually recognize you coming and I do know folks recognize the content material you create as properly” – Andy Jassy


{kind=link}