MLCommons, the nonprofit entity for measuring synthetic intelligence efficiency, immediately introduced the outcomes of its MLPerf 4.0 benchmarks for AI inference and different workloads.
With spectacular outcomes from each Nvidia Corp.’s and Intel Corp.’s newest chips, the brand new benchmarks spotlight the dramatic tempo of evolution within the AI {hardware} business.
MLPerf has turn out to be the business gold normal for AI information middle benchmarks, that are a collection of checks designed to match the pace of AI-optimized processors as they carry out quite a lot of widespread duties. The seller-neutral outcomes are helpful principally to information middle operators, which may use them to information their buying choices when shopping for new AI infrastructure.
The benchmarks assist present how properly numerous graphics processing items and central processing items carry out on quite a lot of duties, together with inference and coaching workloads. The MLPerf 4.0 benchmarks noticed greater than 20 chipmakers take part, with Nvidia and Intel being the primary standouts.
MLCommons final printed its MLPerf 3.1 ends in September 2023, and plenty of new {hardware} has come onto the market since then, with chipmakers engaged in a race to optimize and enhance their silicon chips to speed up AI. So it’s no shock that the MLPerf 4.0 outcomes present marked enhancements from most members.
It’s notable that the MLPerf inference benchmark was up to date for the most recent spherical of checks. Whereas MLPerf 3.1’s benchmark concerned the GPT-J 6B parameter mannequin for textual content summarization, the latest benchmarks use Meta Platforms Inc.’s open-source Llama 2 70B mannequin as the usual. As well as, MLPerf 4.0 additionally features a first-ever benchmark for AI picture technology, utilizing Stability AI Ltd.’s Steady Diffusion mannequin.
Nvidia crushes inference checks with 3X enchancment
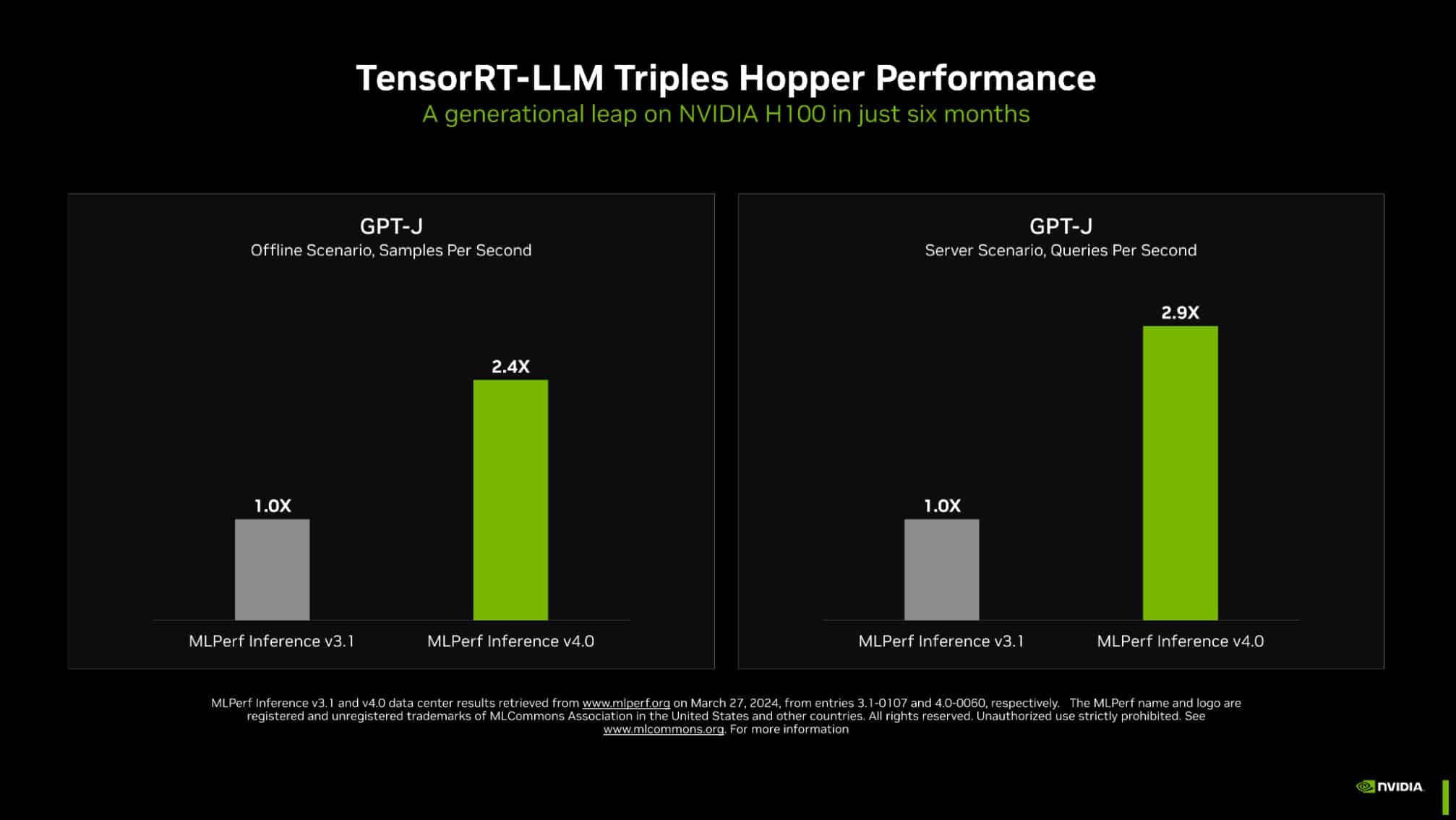
Nvidia is essentially the most dominant chipmaker within the AI business and there are good causes for that, as the most recent benchmarks reveal. The corporate delivered spectacular outcomes throughout the board, exhibiting enhancements not solely with its newest {hardware}, but in addition with a few of its present AI accelerators. As an example, utilizing its TensorRT-LLM open-source inference know-how, the corporate managed to triple the previously-benchmarked efficiency of its H100 Hopper GPU in textual content summarization.
In a media briefing, Nvidia’s director of accelerated computing, Dave Salvator, careworn that the corporate had managed to triple the efficiency of the H100 GPU in simply six months. “We’re very, very happy with this outcome,” he stated. “Our engineering staff simply continues to do nice work to seek out methods to extract extra efficiency from the Hopper structure.”
Nvidia has not but benchmarked its most superior chip, the Blackwell GPU that was introduced at its GTC 2024 occasion simply final week, however that processor will nearly actually outperform the H100 chip when it does. Salvator couldn’t say when Nvidia plans to benchmark Blackwell’s efficiency, however stated he hopes it is going to be ready to take action within the close to future.
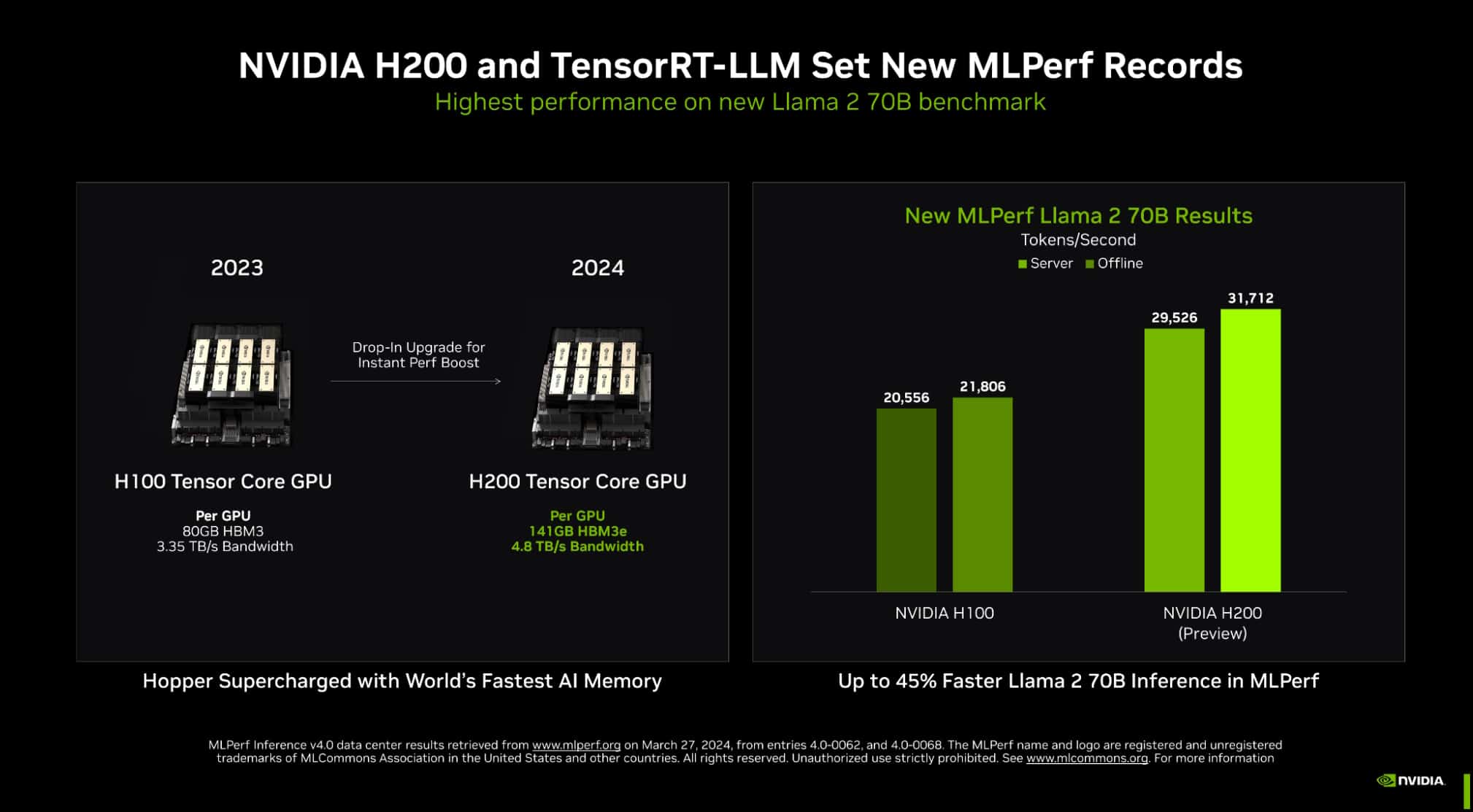
Nvidia did showcase the outcomes of its newer H200 GPU, which is the second-generation of its Grace Hopper architecture-based GPU, and it delivered vital enhancements over the H100. As an example, it was rated 45% quicker when being examined for inference on Llama 2.
Intel exhibits it’s nonetheless related
Intel is best identified for its CPUs than its GPUs, and which means it has been left behind in an AI business that locations such excessive worth on the latter. Nevertheless, it does compete within the GPU business with its Intel Gaudi 2 AI accelerator chip, and the corporate careworn that it’s at present the one benchmarked different to Nvidia’s GPUs.
The chipmaker participated in MLPerf 4.0 with Gaudi and likewise its Xeon CPU chips, and each confirmed some spectacular positive factors in contrast with the earlier set of benchmarks. Whereas Gaudi’s total efficiency nonetheless trails Nvidia’s H100, Intel stated the outcomes it truly delivers higher price-performance than its rival.
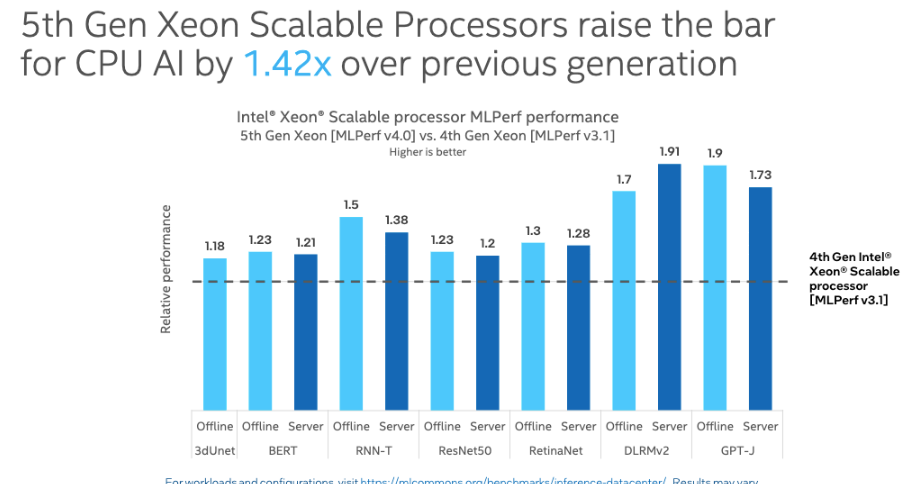
As well as, the fifth Gen Intel Xeon CPU displayed a big enchancment when it comes to efficiency, operating 1.4 instances quicker than the older 4th Gen Intel Xeon CPU within the inference take a look at on Llama 2. Within the the GPT-J LLM textual content summarization benchmark, the most recent Xeon chip confirmed that it was 1.9-times quicker than its predecessor.
The outcomes are essential, as a result of whereas essentially the most highly effective AI fashions are educated on GPUs and use these chips for inference, many smaller fashions are as a substitute being run on CPUs, that are less expensive and simpler to acquire.
Ronak Shah, Intel’s AI product director for Xeon, stated the corporate acknowledges that many enterprises are deploying AI functions in “blended basic function and AI environments.” Consequently, the corporate has centered its efforts “designing CPUs that mesh collectively, with sturdy basic function capabilities with our AMX engine.”
Setting the requirements to beat
The most recent MLPerf benchmarks present greater than 8,500 outcomes, testing nearly each conceivable mixture of AI {hardware} and software program functions. In accordance with MLCommons founder and Government Director David Kanter, the purpose is not only to point out which kind of chip is finest wherein situation, however to ascertain efficiency metrics that chipmakers can construct upon to enhance the capabilities of their merchandise. “The entire level is that when we are able to measure these items, we are able to begin bettering them,” he stated in a briefing.
As well as, certainly one of MLCommons’ acknowledged targets is to align the chipmaking business, with every benchmark that includes the identical datasets and configuration parameters for various chips and software program functions. It’s a standardized strategy that allows information middle operators to make extra knowledgeable choices with regards to selecting essentially the most acceptable AI structure for a selected workload.
Be a part of the group that features greater than 15,000 #CubeAlumni consultants, together with Amazon.com CEO Andy Jassy, Dell Applied sciences founder and CEO Michael Dell, Intel CEO Pat Gelsinger, and plenty of extra luminaries and consultants.
“TheCUBE is a crucial accomplice to the business. You guys actually are part of our occasions and we actually respect you coming and I do know folks respect the content material you create as properly” – Andy Jassy


{kind=link}